


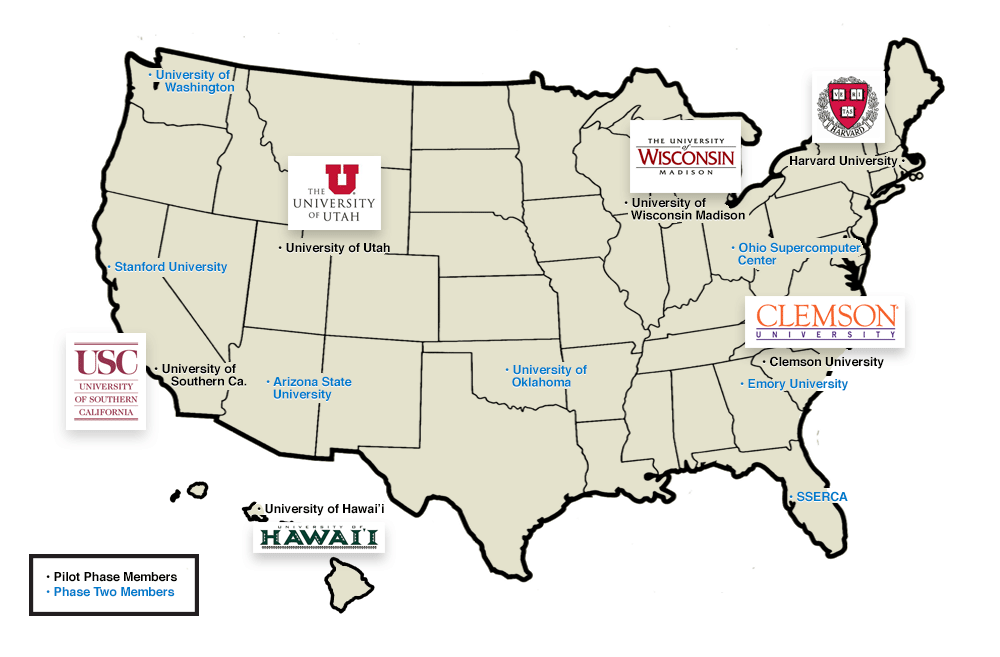
 Back in March, Research Computing announced its collaboration with five universities to launch a new national program that would broaden the impact of advanced computing resources at university campuses across the country. The NSF funded program was called Advanced Cyberinfrastructure - Research and Educational Facilitation: Campus-based Computational Research Support or ACI-REF for short. The program received $5.3M in funding and was based on the concept of condominium computing - instead of users buying and maintaining their own personal clusters, users would buy computing nodes and these resources would be committed to a larger shared cluster, managed and supported by their IT organizations.
Back in March, Research Computing announced its collaboration with five universities to launch a new national program that would broaden the impact of advanced computing resources at university campuses across the country. The NSF funded program was called Advanced Cyberinfrastructure - Research and Educational Facilitation: Campus-based Computational Research Support or ACI-REF for short. The program received $5.3M in funding and was based on the concept of condominium computing - instead of users buying and maintaining their own personal clusters, users would buy computing nodes and these resources would be committed to a larger shared cluster, managed and supported by their IT organizations.
In addition to fostering the condo model of computing, the program also set out to widen the reach of high performance computing by bringing new users into the fold and helping others master the art of high end computation. To achieve this goal, Research Computing hired Bob Freeman to be Harvard's first ACI-REF. Bob joined RC in May and has spent the last couple of months reaching out to new and current users of RC's resources. As an ACI-REF, Bob works closely with students, faculty, and staff to ensure they are making the most of RC's cluster, Odyssey. By introducing new users to the power of large-scale computing and showing current users how to best optimize their jobs, Bob is helping researchers get faster results, increase output, and improve workflow. Below are three short success stories of just that - researchers working with Bob to solve problems and win at science!
Audit That: Looking at workflows to maximize throughput
 As part of the Genotype-Tissue Expression project, researchers examined up to five gene expression profiles of human tissues (out of a possible 10), for 200 patients resulting in a total of 1000 samples. The large number of samples made it difficult for the research group to push data through their workflow. At their current computation rate, they estimated their initial analysis would take anywhere from 3 to 6 months. Such a timeframe was less than agreeable as the team hoped to have analyses ready to present at a conference in late June.
As part of the Genotype-Tissue Expression project, researchers examined up to five gene expression profiles of human tissues (out of a possible 10), for 200 patients resulting in a total of 1000 samples. The large number of samples made it difficult for the research group to push data through their workflow. At their current computation rate, they estimated their initial analysis would take anywhere from 3 to 6 months. Such a timeframe was less than agreeable as the team hoped to have analyses ready to present at a conference in late June.
To see if and where time savings would be possible, Bob audited their workflow, examined technical metrics (CPU usage, IO, etc.), and reviewed parameter usage for several of the informatics apps that created bottlenecks for the analysis. The audit revealed a number of adjustments that could be made to optimize workflow:
- Limiting the numbers of cores requested to ensure that the nodes were not oversubscribed.
- Limiting core allocation to one node so that processes were not orphaned on other nodes.
- Moving the high volume of file IO to RC's fast regal filesystem and off slower lab disk shares.
- Changing several parameters in an informatics program that intended to help their workflow but actually slowed it down.
- Including multithread options for a different informatics program.
- Verifying with software authors that "test data" runs were not indicative of scaled performance and could generate erroneous results.
- Ensuring they were fully utilizing the SLURM reservation system and accessing all special nodes & partitions they were entitled to.
With these changes, an original compute time for 3-6 months was reduced to 3 weeks and the researchers met their immediate deadline.
Waste Not Want Not: Managing CPU usage to ensure shared success
 Since the Odyssey cluster is a shared resource, it is imperative that all users treat it as such. Like anything shared by the community, there are rules of conduct and etiquette that ensure enjoyment for all. RC regularly generates utilization reports to make sure the cluster is meeting the needs of the user community. One such report indicated that three users wasted more than 23 CPU years of compute over the course of a day. Although the individuals had hoped to speed up their analysis by using a large number of cores, because these users did not specify that all the cores should be running on one machine CPU hours were wasted.
Since the Odyssey cluster is a shared resource, it is imperative that all users treat it as such. Like anything shared by the community, there are rules of conduct and etiquette that ensure enjoyment for all. RC regularly generates utilization reports to make sure the cluster is meeting the needs of the user community. One such report indicated that three users wasted more than 23 CPU years of compute over the course of a day. Although the individuals had hoped to speed up their analysis by using a large number of cores, because these users did not specify that all the cores should be running on one machine CPU hours were wasted.
In addition, the users' programs were not MPI-enabled, which allows threads to talk to one another to coordinate use of memory and data. This resulted in cores on other nodes remaining idle, tying up resources, and causing the users' job to run slowly and inefficiently. To resolve this, Bob contacted the users, notifying them of the resources they reserved and their inefficient use, and offered to help them optimize their work. After conversations, two of the three reviewed their methods and made changes to their code and HPC usage. The mistakes in the code were not-so-obvious errors and that combined with ignorance about multicore usage across compute nodes led to wasted resources.
The Ropes: Helping new users tackle HPC and informatics
 Two new users were having difficulties handling large files and large numbers of files. Both were also about to start de novo assembly and abundance estimation RNA-Seq workflows for the first time. Bob provided guidance on the workflow, parameter usage, shell/HPC shortcuts, and downstream analysis procedures. One of the users saw a drop of 50% in compute time.
Two new users were having difficulties handling large files and large numbers of files. Both were also about to start de novo assembly and abundance estimation RNA-Seq workflows for the first time. Bob provided guidance on the workflow, parameter usage, shell/HPC shortcuts, and downstream analysis procedures. One of the users saw a drop of 50% in compute time.